Week 3 (16th June to 22nd June)
I resolved this issue and benchmarked the partial_trace function from both QuTiPy and toqito.
The initial write-ups and methodology can be found in this comment.
Below are the results, Full results here:
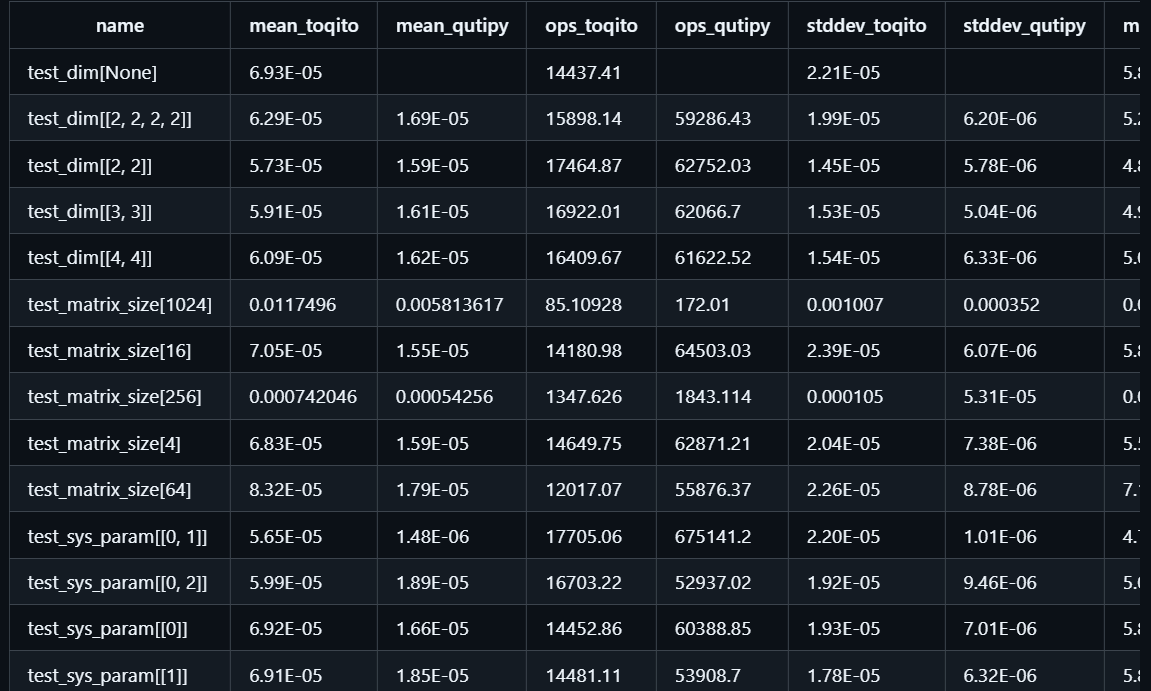
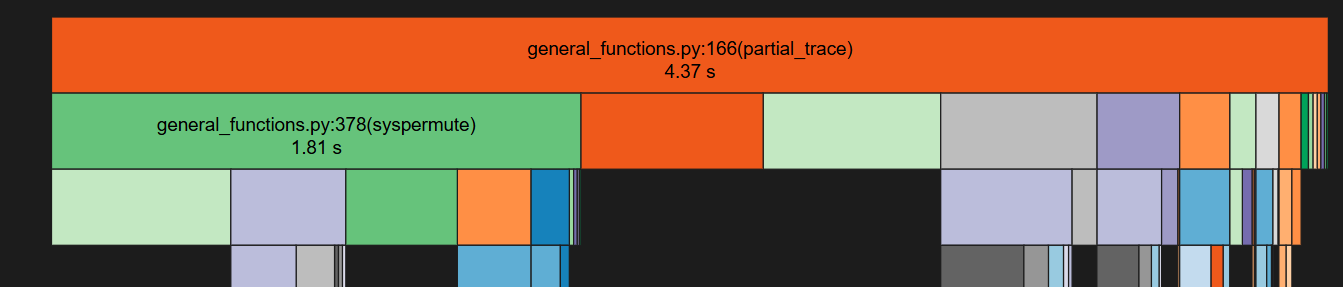
To compare performance, I calculated speedup using the ratio mean_toqito / mean_qutipy. Basic profiling revealed that in both implementations, the permute_systems function is the primary bottleneck, accounting for nearly half the total runtime.
For QuTIPy:
For toqito:
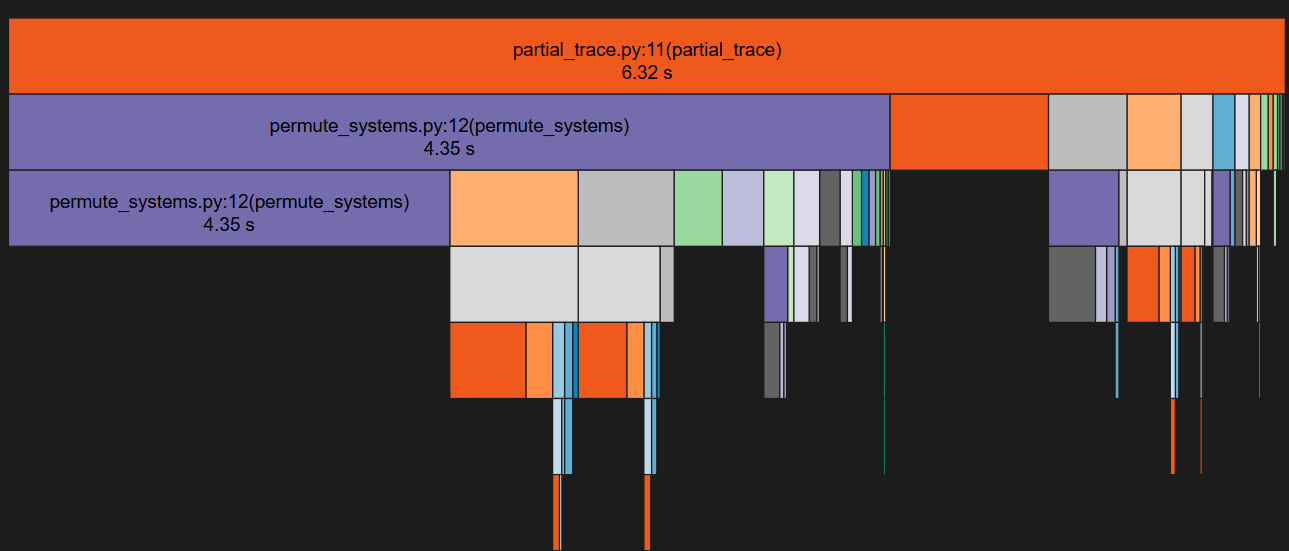
While profiling, I discovered that the check is_vec = np.min(input_mat_dims) == 1 was a surprising bottleneck. Replacing it with a simpler condition — input_mat_dims[0] == 1 or input_mat_dims[1] == 1 — led to a significant speedup of over 20x (roughly 27.5x in some cases). Interestingly, I noticed that despite this local optimization, the total execution time occasionally increased, which is something I’m looking to investigate further. More details here
We overcame the major bottleneck of identifying corresponding functions across libraries, which marked a significant breakthrough. The discussion can be found here. Vincent and I finalized the list of benchmarking identifiers in this comment.
The week concluded with the completion of benchmarks for the channel_ops/ module in toqito.